How to get comment balloons to reappear in the margins of a MS Word document:
- Review>Show Comments>List
Then:
- Review>Show Markup>Balloons>Show All Revisions Inline
How to get comment balloons to reappear in the margins of a MS Word document:
Then:
How to enable root access in WinSCP:
sudo /usr/lib/openssh/sftp-server
How to withdraw money from a Commonwealth Bank ATM using your phone and the CommBank App.
On the ATM screen, select “Cardless Cash”
In the CommBank app go to 'Pay' > 'Cardless Withdrawal & Deposit ".
Using your phone, scan the QR code on the ATM screen.
How to search for a file on linux and suppress error messages and stop once the first instance is found:
find /home/files -xdev -type f -name 'P13.txt' -print -quit 2>/dev/null
How to show fold changes in an excel spreadsheet when there are 0 values in the denominator. In the example below P30 is the numerator and P2 is the denominator. The logic is:
Both numerator and denominator = 0 → output 0.00
Denominator = 0, numerator ≠ 0 → output >{numerator} (2 decimals)
Numerator = 0, denominator ≠ 0 → output <{denominator} (2 decimals)
Otherwise → output normal division with 2 decimals.
=IF(AND(P30=0,P2=0),"0.00",
IF(P2=0,">"&TEXT(P30,"0.00"),
IF(P30=0,"<"&TEXT(P2,"0.00"),
TEXT(P30/P2,"0.00"))))
How to apply for a Visa on Arrival for Indonesia online before you travel:
A Visa on Arrival (VOA) is available for passport holders in many countries including Australia. It costs US$35 (A$50) and is valid for 30 days. Follow the link below to apply.
How to re-use a file channel and indeterminate number of times (eg combining with a channle with an unknkown number of elements in NextFlow DSL1:
process collectGVCF {
publishDir "${params.combined_1_vcf}", mode: 'copy'
output:
set val(pair_id), val(round), file("${pair_id}_raw_variants_${round}.vcf.gz") into collected_vcf
}
// Later after splitting:
sample_files
.map { it -> it.getBaseName() }
.combine(Channel.fromPath("${params.combined_1_vcf}/*_raw_variants_1.vcf.gz"))
.set { reuse_pairs }
How to conditionally choose from two channels in NextFlow:
grouped_interval_vcf_ch=(params.splitIntervalOverlapLength && params.splitIntervalOverlapLength.toInteger() > 0
? trimmed_vcf_ch
: interval_vcfs_3
)
How to collect all files related by prefix in NextFlow:
Example input channel:
interval_bams_ch:
[ file('73-50_L001_raw_variants_1.bam') ]
[ file('73-50_L001_raw_variants_2.bam') ]
[ file('73-50_L002_raw_variants_1.bam') ]
[ file('73-50_L002_raw_variants_2.bam') ]
Process code:
bam_name_parts_ch = interval_bams_ch.map { file ->
def name = file.baseName.replaceFirst(/_raw_variants_.*/, '')
tuple(name, file)
}.groupTuple()
Example output:
[ '73-50_L001', [file('73-50_L001_raw_variants_1.bam'), file('73-50_L001_raw_variants_2.bam')] ]
[ '73-50_L002', [file('73-50_L002_raw_variants_1.bam'), file('73-50_L002_raw_variants_2.bam')] ]
How to collect all files from one channel and associate/combine them with elements of another channel in NextFlow:
Example Input channels:
bam_for_collect_ch2:
[ file('73-50_L002.bam') ]
[ file('73-50_L001.bam') ]
interval_vcfs_3:
[ file('73-50_L001_raw_variants_1.vcf.gz') ]
[ file('73-50_L001_raw_variants_2.vcf.gz') ]
[ file('73-50_L002_raw_variants_1.vcf.gz') ]
[ file('73-50_L002_raw_variants_2.vcf.gz') ]
Process code:
input:
set val(pair_id), val(all_vcf) from bam_for_collect_ch2.map({ file -> file.baseName }).combine(interval_vcfs_3.collect().map({ file -> file.baseName }).toList())
Example output:
[ '73-50_L002', ['73-50_L002_raw_variants_1.vcf.gz', '73-50_L002_raw_variants_2.vcf.gz'] ]
[ '73-50_L001', ['73-50_L001_raw_variants_1.vcf.gz', '73-50_L001_raw_variants_2.vcf.gz'] ]
How to get rid of "WARNING : No mitochondrion chromosome found" in SnpEff:
Prefix the contig name with MT.
How to clone a public GitHub repository with VS Code and push it to a private GitHub repository.
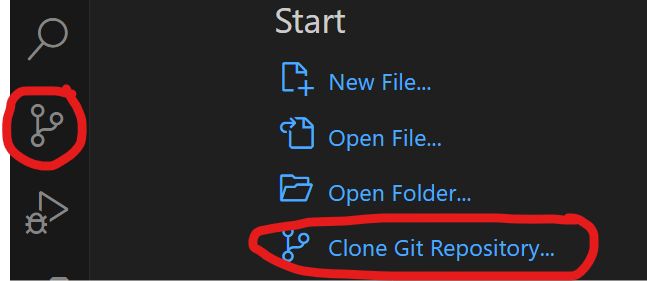
Open a terminal in VS Code (View>terminal)
PS C:\Users\github> cd sarek
PS C:\Users\github\sarek> git remote remove origin
PS C:\Users\github\sarek> git remote add origin https://github.com/ink-blot/sarek.git
PS C:\Users\github\sarek> git branch
* master
PS C:\Users\github\sarek> git push -u origin master
If it doesn't promptly start pushing, an authorisation screen should (eventually) appear (it may take a few minutes).
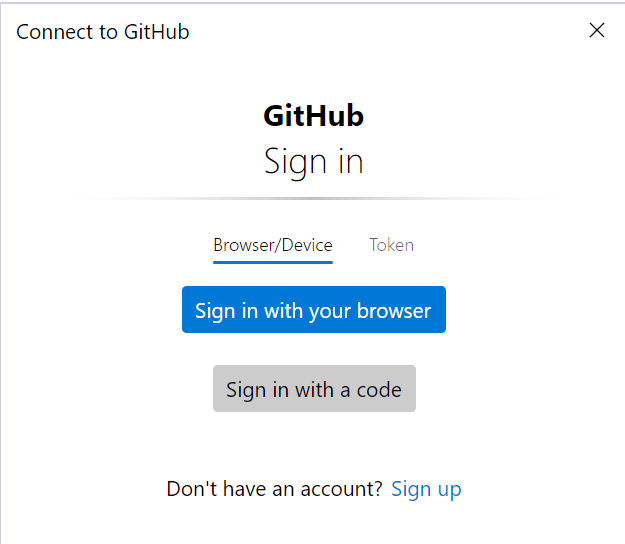
The token method is preferred:
Optional steps if you want to fetch updates from the original nf-core/sarek repository in the future, add it as an upstream remote:
PS C:\Users\github\sarek> git remote add upstream https://github.com/nf-core/sarek.git
PS C:\Users\github\sarek> git fetch upstream
PS C:\Users\github\sarek> git merge upstream/main
